"Notícia disponible únicament amb finalitats històriques i d'hemeroteca. La informació i enllaços mostrats es corresponen amb els quals estaven operatius a la data de la seua publicació. No es garantix que continuen actius actualment".
16.500 milions d'euros. Eixos són els ingresos que se estima generarán la inteligencia artificial (IA) y los datos en la indústria espanyola per a 2025, segons es va avançar el febrer passat en el fòrum de IndesIA , l'associació per a l'aplicació de la intel·ligència artificial en la indústria. La IA ja forma part del nostre dia a dia : ja siga fent més senzill el nostre treball en realitzar tasques rutinàries i repetitives, o ben complementant les capacitats humanes en diversos àmbits a través de models d'aprenentatge automàtic que faciliten, per exemple, el reconeixement d'imatges, la traducció automàtica o la predicció de diagnòstics mèdics. Totes elles, activitats que ens ajuden a millorar l'eficiència de negocis i servicis, impulsant una presa de decisions més precisa.
, l'associació per a l'aplicació de la intel·ligència artificial en la indústria. La IA ja forma part del nostre dia a dia : ja siga fent més senzill el nostre treball en realitzar tasques rutinàries i repetitives, o ben complementant les capacitats humanes en diversos àmbits a través de models d'aprenentatge automàtic que faciliten, per exemple, el reconeixement d'imatges, la traducció automàtica o la predicció de diagnòstics mèdics. Totes elles, activitats que ens ajuden a millorar l'eficiència de negocis i servicis, impulsant una presa de decisions més precisa.
Però perquè els models d'aprenentatge automàtic (també coneguts pel terme en anglés machine learning ) funcionen correctament, es necessiten dades de qualitat i ben documentats. Tot model d'aprenentatge automàtic s'entrena i avalua amb dades. Les característiques d'estos conjunts de dades condicionen el comportament del model. Per exemple, si les dades d'entrenament reflectixen biaixos socials no desitjats és probable que estos també s'incorporen en el model, la qual cosa pot tindre greus conseqüències quan s'utilitza en àmbits de gran importància, com la justícia penal, la contractació de persones o el préstec de crèdits. A més, si no coneixem el context de les dades, pot ser que el nostre model no funcione correctament, ja que en el seu procés de construcció no s'han tingut en compte les característiques intrínseques de les dades sobre els quals se sustenta.
Per estes i altres raons, el Foro Económico Mundial suggerix que totes les entitats han de documentar la procedència, la creació i l'ús dels conjunts de dades d'aprenentatge automàtic amb la finalitat d'evitar resultats erronis o discriminatoris.
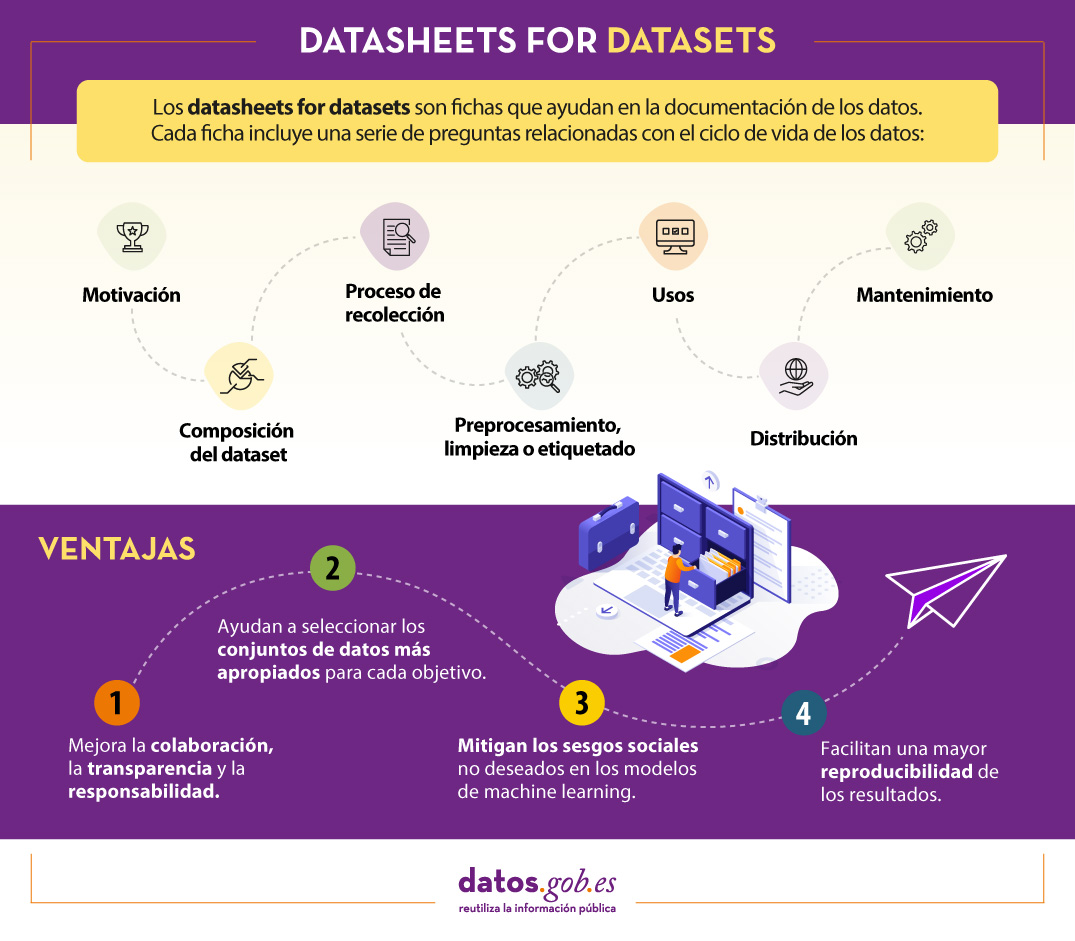
Què són Datasheets for datasets?
Un mecanisme per a documentar esta informació són les conegudes com Datasheets for datasets . Este marc de treball proposa que tot conjunt de dades ha de ser acompanyat d'una “fitxa de dades”, cridada datasheet, que consistix d'un qüestionari que guia en la documentació de les dades i la reflexió al llarg del cicle de vida de les dades. Algunes dels avantatges que suposa són:
- Millora la col·laboració, la transparència i la responsabilitat dins de la comunitat d'aprenentatge automàtic.
- Mitiga els biaixos socials no desitjats en els models.
- Ajuda als investigadors i desenvolupadors a seleccionar els conjunts de dades més apropiades per a aconseguir els seus objectius específics.
- Facilita una major reproducibilidad dels resultats.
Els datasheets variaran depenent de factors tals com l'àrea de coneixement, la infraestructura organisacional existent o els fluxos de treball.
Per a ajudar en la creació de les datasheet, s'ha dissenyat un qüestionari amb una sèrie de preguntes, concordes a les etapes del cicle de vida de les dades:
- Motivació. Recoge les raons que han portat a la creació dels conjunts de dades. També es pregunta sobre qui va crear o va finançar dits datasets.
- Composició. Ofrece als usuaris la informació necessària sobre l'adequació del conjunt de dades als seus objectius. Inclou, entre altres preguntes, quines unitats d'observació representen el conjunt de dades (documents, fotos, persones, països), quin tipus d'informació oferix cada unitat o si hi ha errors, fonts de soroll o redundàncies en ell. Reflexiona sobre les dades que es referixen a persones per a evitar possibles biaixos socials o violacions a la privacitat.
- Procés de recol·lecció. El seu objectiu és ajudar als investigadors i usuaris a pensar en com crear conjunts de dades alternatives amb similars característiques. Ací es detalla, per exemple, com es van adquirir les dades, qui va participar en el procés de recopilació o com va ser el procés de revisió ètica. Tracta especialment els aspectes ètics del processament de dades protegides per la RGPD.
- Preprocesamiento, limpieza o etiquetado. Gracias a estas preguntas, los usuarios de datos podrán determinar si estos han sido procesados de formas compatibles con los usos que les pretenden dar. Indaga sobre si se realizó algún preprocesamiento, limpieza o etiquetado de los datos, o si está disponible el software que se utilizó para preprocesarlos, limpiarlos y etiquetarlos.
- Usos. Esta secció proporciona informació sobre aquelles tasques per a les quals les dades poden o no poden ser usats. Per a açò, s'ha de respondre a preguntes com: El conjunt de dades ja ha sigut usat per a alguna tasca? Para quin altres tasques poden ser utilitzats? La composició del conjunt de dades o la forma en què es va recopilar, preprocesó, va netejar i va etiquetar pot afectar a altres usos futurs?
- Distribució. Recoge com es difondrà el conjunt de dades. Les preguntes se centren en si les dades es distribuiran a tercers i, en cas afirmatiu, com, quan, quins són les restriccions d'ús i baix quines llicències.
- Mantenimiento. El qüestionari finalitza amb preguntes dirigides a planificar el manteniment de les dades i comunicar el pla als usuaris de les dades. Per exemple, es respon a si s'actualitzarà el conjunt de dades o qui donarà suport.
Es recomana que totes les preguntes siguen tingudes en compte abans de la recol·lecció de les dades, perquè els seus creadors puguen ser conscients dels possibles problemes. Per a il·lustrar com es podria respondre a cadascuna d'elles en la pràctica, els creadors del model han elaborat un apèndix amb un exemple per a un conjunt de dades determinat.
És efectiu Datasheets for datasets?
El marc per a documentar les dades Datasheets for datasets ha rebut inicialment bones crítiques, però la seua implementació continua implicant diversos reptes, sobretot quan es treballa amb dades dinàmiques.
Per a conéixer si el marc resol de forma efectiva les necessitats de documentació dels creadors i els usuaris de les dades, al juny del 2022, Microsoft USA i la Universitat de Michigan van dur a terme un estudie sobre la seua implementació . Per a açò van realitzar una sèrie d'entrevistes i un seguiment de l'aplicació del qüestionari per part de diversos professionals de l'aprenentatge automàtic.
En resum, els participants van expressar la necessitat que els marcs de documentació siguen adaptables als diferents contextos, s'integren en les ferramentes existents i en els fluxos de treball, i que siguen tan automatitzats com siga possible, hagut d'en part a l'extensió de les preguntes. No obstant açò, també van ressaltar els seus avantatges, com, per exemple, que reduïx el risc de pèrdua d'informació, promou la col·laboració entre tots els que participen en el cicle de vida de les dades, facilita el descobriment de les dades o impulsa el pensament crític, entre unes altres.
En definitiva, ens trobem davant un bon punt de partida, però que haurà d'evolucionar, sobretot per a adaptar-se a les necessitats de les dades dinàmiques i als fluxos de documentació aplicats en diferents contextos.
Font original de la notícia
- Informació i dades del sector públic





