"Noticia dispoñible unicamente con fins históricos e de hemeroteca. A información e ligazóns mostradas correspóndense cos que estaban operativos á data da súa publicación. Non se garante que continúen activos actualmente".
16.500 millóns de euros. Eses son os ingresos que se estima xerarán a intelixencia artificial (IA) e os datos na industria española para 2025, segundo avanzouse o pasado febreiro no foro de IndesIA , a asociación para a aplicación da intelixencia artificial na industria. A IA xa forma parte do noso día a día : xa sexa facendo máis sinxelo o noso traballo ao realizar tarefas rutineiras e repetitivas, ou ben complementando as capacidades humanas en diversos ámbitos a través de modelos de aprendizaxe automática que facilitan, por exemplo, o recoñecemento de imaxes, a tradución automática ou a predición de diagnósticos médicos. Todas elas, actividades que nos axudan a mellorar a eficiencia de negocios e servizos, impulsando unha toma de decisións máis certeira.
, a asociación para a aplicación da intelixencia artificial na industria. A IA xa forma parte do noso día a día : xa sexa facendo máis sinxelo o noso traballo ao realizar tarefas rutineiras e repetitivas, ou ben complementando as capacidades humanas en diversos ámbitos a través de modelos de aprendizaxe automática que facilitan, por exemplo, o recoñecemento de imaxes, a tradución automática ou a predición de diagnósticos médicos. Todas elas, actividades que nos axudan a mellorar a eficiencia de negocios e servizos, impulsando unha toma de decisións máis certeira.
Pero para que os modelos de aprendizaxe automática (tamén coñecidos polo termo en inglés machine learning ) funcionen correctamente, necesítanse datos de calidade e ben documentados. Todo modelo de aprendizaxe automática adéstrase e avalía con datos. As características destes conxuntos de datos condicionan o comportamento do modelo. Por exemplo, se os datos de adestramento reflicten rumbos sociais non desexados é probable que estes tamén se incorporen no modelo, o cal pode ter graves consecuencias cando se utiliza en ámbitos de gran importancia, como a xustiza penal, a contratación de persoas ou o préstamo de créditos. Ademais, se non coñecemos o contexto dos datos, poida que o noso modelo non funcione correctamente, xa que no seu proceso de construción non se tiveron en conta as características intrínsecas dos datos sobre os cales se sustenta.
Por estas e outras razóns, o Foro Económico Mundial suxire que todas as entidades deben documentar a procedencia, a creación e o uso dos conxuntos de datos de aprendizaxe automática co fin de evitar resultados erróneos ou discriminatorios.
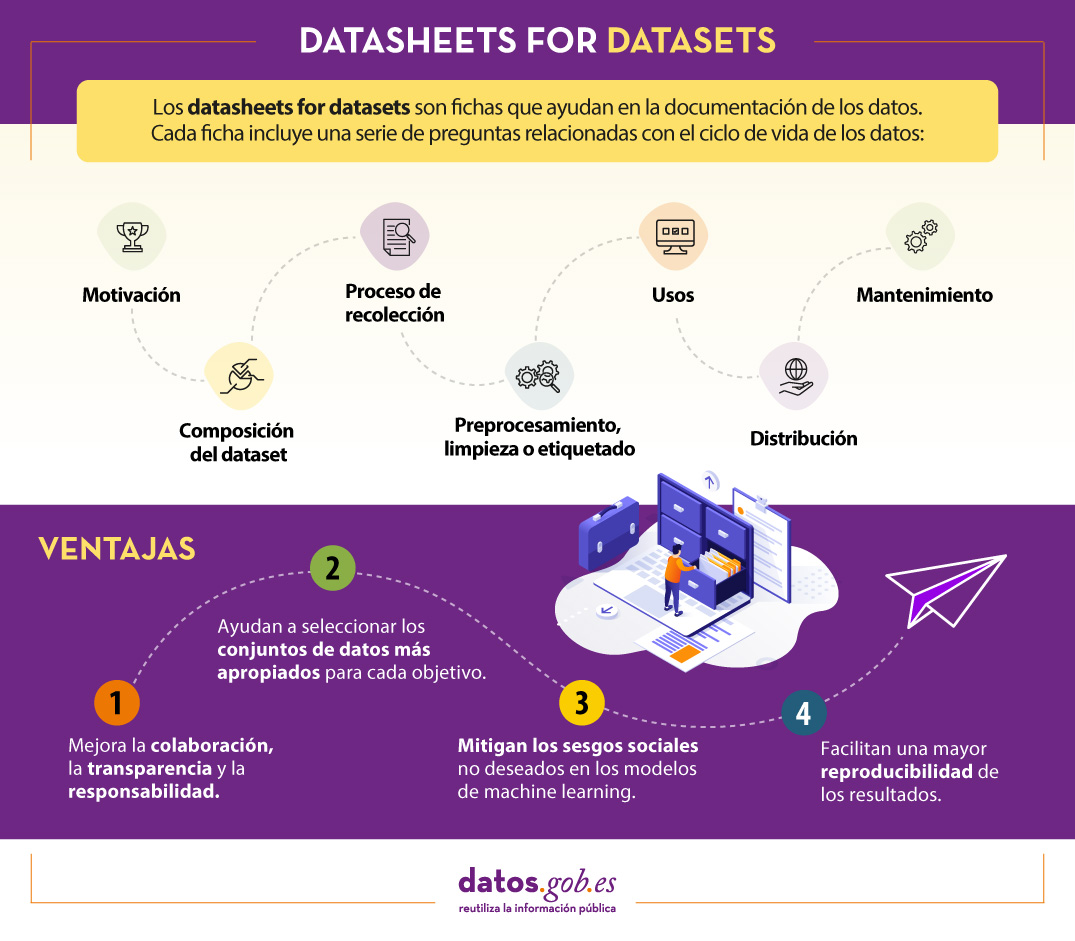
Que son Datasheets for datasets?
Un mecanismo para documentar esta información son as coñecidas como Datasheets for datasets . Este marco de traballo propón que todo conxunto de datos debe ser acompañado dunha “ficha de datos”, chamada datasheet, que consiste de un cuestionario que guía na documentación dos datos e a reflexión ao longo do ciclo de vida dos datos. Algunhas das vantaxes que supón son:
- Mellora a colaboración, a transparencia e a responsabilidade dentro da comunidade de aprendizaxe automática.
- Mitiga os rumbos sociais non desexados nos modelos.
- Axuda aos investigadores e desenvolvedores a seleccionar os conxuntos de datos máis apropiados para alcanzar os seus obxectivos específicos.
- Facilita unha maior reproducibilidad dos resultados.
Os datasheets variarán dependendo de factores tales como a área de coñecemento, a infraestrutura organizacional existente ou os fluxos de traballo.
Para axudar na creación de as datasheet, deseñouse un cuestionario cunha serie de preguntas, acordes ás etapas do ciclo de vida dos datos:
- Motivación. Recoge as razóns que levaron á creación dos conxuntos de datos. Tamén se pregunta sobre quen creou ou financiou este datasets.
- Composición. Ofrece aos usuarios a información necesaria sobre a adecuación do conxunto de datos aos seus obxectivos. Inclúe, entre outras preguntas, que unidades de observación representan o conxunto de datos (documentos, fotos, persoas, países), que tipo de información ofrece cada unidade ou se hai erros, fontes de ruído ou redundancias nel. Reflexiona acerca dos datos que se refiren a persoas para evitar posibles rumbos sociais ou violacións á privacidade.
- Proceso de recolección. O seu obxectivo é axudar aos investigadores e usuarios a pensar en como crear conxuntos de datos alternativos con similares características. Aquí detállase, por exemplo, como se adquiriron os datos, quen participou no proceso de recompilación ou como foi o proceso de revisión ética. Trata especialmente os aspectos éticos do procesamento de datos protexidos pola RGPD.
- Preprocesamiento, limpeza ou etiquetaxe. Grazas a estas preguntas, os usuarios de datos poderán determinar se estes foron procesados de formas compatibles cos usos que lles pretenden dar. Indaga sobre se se realizou algún preprocesamiento, limpeza ou etiquetaxe dos datos, ou se está dispoñible o software que se utilizou para preprocesarlos, limpalos e etiquetarlos.
- Usos. Esta sección proporciona información sobre aquelas tarefas para as cales os datos poden ou non poden ser usados. Para iso, débese responder a preguntas como: El conxunto de datos xa foi usado para algunha tarefa? Para que outras tarefas poden ser utilizados? A composición do conxunto de datos ou a forma en que se recompilou, preprocesó, limpou e etiquetó pode afectar a outros usos futuros?
- Distribución. Recoge como se difundirá o conxunto de datos. As preguntas céntranse en se os datos distribuiranse a terceiros e, en caso afirmativo, como, cando, cales son as restricións de uso e baixo que licenzas.
- Mantenimiento. O cuestionario finaliza con preguntas dirixidas a planificar o mantemento dos datos e comunicar o plan aos usuarios dos datos. Por exemplo, respóndese a se se actualizará o conxunto de datos ou quen dará soporte.
Recoméndase que todas as preguntas sexan tidas en conta antes da recolección dos datos, para que os seus creadores poidan ser conscientes dos posibles problemas. Para ilustrar como se podería responder a cada unha delas na práctica, os creadores do modelo elaboraron un apéndice cun exemplo para un conxunto de datos determinado.
É efectivo Datasheets for datasets?
O marco para documentar os datos Datasheets for datasets recibiu inicialmente boas críticas, pero a súa implementación continúa carrexando diversos retos, sobre todo cando se traballa con datos dinámicos.
Para coñecer se o marco resolve de forma efectiva as necesidades de documentación dos creadores e os usuarios dos datos, en xuño do 2022, Microsoft USA e a Universidade de Michigan levaron a cabo un estudo sobre a súa implementación . Para iso realizaron unha serie de entrevistas e un seguimento da aplicación do cuestionario por parte de varios profesionais da aprendizaxe automática.
En resumo, os participantes expresaron a necesidade de que os marcos de documentación sexan adaptables aos diferentes contextos, intégrense nas ferramentas existentes e nos fluxos de traballo, e que sexan tan automatizados como sexa posible, debido en parte á extensión das preguntas. No entanto, tamén resaltaron as súas vantaxes, como, por exemplo, que reduce o risco de perda de información, promove a colaboración entre todos os que participan no ciclo de vida dos datos, facilita o descubrimento dos datos ou impulsa o pensamento crítico, entre outras.
En definitiva, atopámonos ante un bo punto de partida, pero que deberá evolucionar, sobre todo para adaptarse ás necesidades dos datos dinámicos e aos fluxos de documentación aplicados en diferentes contextos.
Fonte orixinal da noticia
- Información e datos do sector público





