O perfilado de datos é o conxunto de actividades e procesos destinados a determinar os metadatos sobre un conxunto concreto de datos. Este proceso, considerado como unha técnica indispensable durante a análises exploratorio de datos , inclúe a aplicación de distintos estatísticos co principal obxectivo de determinar aspectos como o número de valores nulos, a cantidade de valores distintos nunha columna, os tipos de datos e/ou os patróns máis frecuentes dos valores dos datos. O seu obxectivo final é proporcionar un entendemento claro e detallado da estrutura, contido e calidade dos datos, o que é esencial antes do seu uso en calquera aplicación.
A importancia do perfilado de datos, tipos e ferramentas
13 xuño 2024

O perfilado de datos é o conxunto de actividades e procesos destinados a determinar os metadatos sobre un conxunto concreto de datos.
Tipos de perfilado de datos
Existen distintas alternativas en canto aos principios estatísticos a aplicar durante un perfilado de datos, así como a súa tipoloxía. Para este artigo realizouse unha revisión de varias aproximacións de distintos autores. Con base niso, decídese centrar o artigo sobre a tipoloxía de técnicas de perfilado de datos en tres categorías de alto nivel: perfilado dunha columna, perfilado multicolumna e perfilado de dependencias. Para cada categoría identifícanse posibles técnicas e usos, como veremos a seguir.
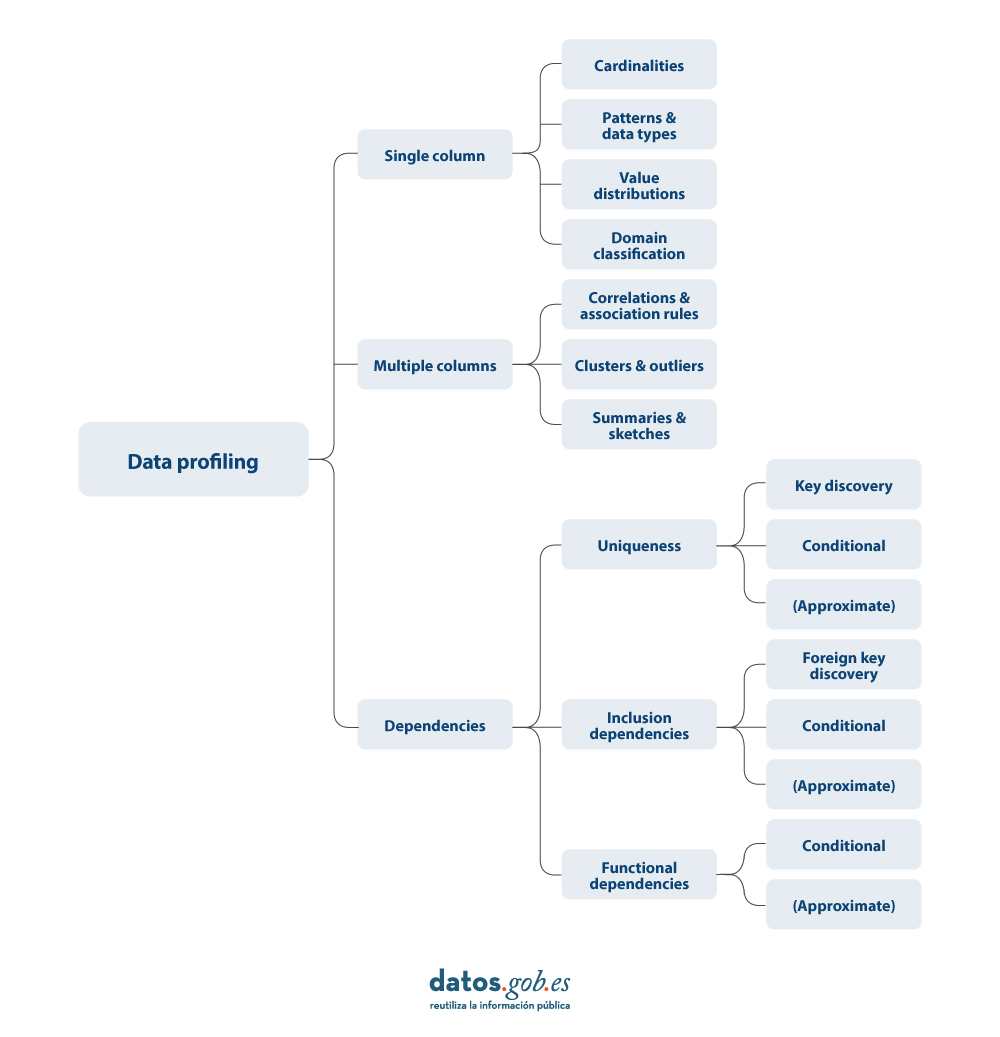
A seguir, preséntase máis detalle sobre cada unha das categorías, así como os beneficios que achegan.
1. Perfilado dunha columna
O perfilado dunha columna céntrase en analizar cada columna dun conxunto de datos de maneira individual. Esta análise inclúe a recompilación de estatísticas descritivas como:
-
Cálculo de valores distintos, para determinar o número exacto de rexistros únicos dunha lista e poder clasificalos. Por exemplo, no caso dun conxunto de datos que recolla as subvencións outorgadas por un organismo público, esta tarefa permitiranos saber cantos beneficiarios distintos hai para a columna de beneficiarios, e se algún se repite.
-
Distribución de valores (frecuencia), que se refire á análise da frecuencia coa que ocorren diferentes valores dentro de una mesma columna. Isto pódese representar mediante histogramas que dividen os valores en intervalos e mostran cantos valores atópanse en cada intervalo. Por exemplo, nunha columna de idades, poderiamos atopar que 20 persoas teñen entre 25-30 anos, 15 persoas teñen entre 30-35 anos, etc.
-
Cálculo de valores nulos ou faltantes, o que implica contar a cantidade de valores nulos ou baleiros en cada columna dun conxunto de datos. Axuda a determinar a completitud dos datos e pode sinalar posibles problemas de calidade. Por exemplo, nunha columna de direccións de correo electrónico, 5 de 100 rexistros poderían estar baleiros, indicando un 5% de datos faltantes.
- Longitud mínima, máxima e media dos valores (para columnas de texto), a cal está orientada a calcular cal é a lonxitude dos valores nunha columna de texto. Isto é útil para identificar valores inusuais e para definir restricións de lonxitude en bases de datos. Por exemplo, nunha columna de nomes, poderiamos atopar que o nome máis curto ten 3 caracteres, o máis longo 20 caracteres, e a media é de 8 caracteres.
Canto aos principais beneficios no uso deste perfilado de datos destacan:
- Detección de anomalías: permite a identificación de valores inusuais ou fóra de rango.
- Mellora da preparación de datos: axuda na normalización e limpeza de datos antes do seu uso en análises máis avanzadas ou en modelos de machine learning.
2. Perfilado multicolumna
O perfilado multicolumna analiza a relación entre dúas ou máis columnas dentro do mesmo conxunto de datos. Este tipo de perfilado pode incluír:
- Análise de correlación, utilizado para identificar relacións entre columnas numéricas nun conxunto de datos. Unha técnica común é calcular correlacións por pares entre todas as columnas numéricas para descubrir patróns de relación. Por exemplo, nunha táboa de investigadores, poderiamos atopar que a idade e o número de publicacións están correlacionados, indicando que a medida que aumenta a idade dos investigadores e a súa categoría, tamén tende a aumentar o seu número de publicacións. Un coeficiente de correlación de Pearson podería cuantificar esta relación.
- Valores atípicos (outliers), o cal implica identificar datos que se desvían significativamente doutros puntos de datos. Os outliers poden indicar erros, variabilidade natural ou puntos de datos interesantes que merecen unha maior investigación. Por exemplo, nunha columna de orzamentos para proxectos de I+D anuais, un valor dun millón de euros podería ser un outlier se a maioría dos ingresos atópanse entre 30.000 e 100.000 euros. Con todo, se se representa o importe en relación á duración do proxecto, podería ser un valor normal se o proxecto dun millón ten 10 veces a duración do de 100.000 euros.
- Detección de combinacións de valores frecuentes, enfocada en atopar conxuntos de valores que ocorren xuntos con frecuencia nos datos. Utilízanse para descubrir asociacións entre elementos, como nos datos de transaccións. Por exemplo, nun conxunto de datos de compras, poderiamos atopar que os produtos "cueiros" e "leite de fórmula para bebés" cómpranse xuntos frecuentemente. Un algoritmo de regras de asociación podería xerar regúlaa {cueiros} → {leite de fórmula}, indicando que os clientes que compran pan tamén tenden a comprar manteiga cunha alta probabilidade.
Canto aos principais beneficios no uso deste perfilado de datos destacan:
- Detección de tendencias: permite identificar relacións e correlacións significativas entre columnas, o que pode axudar na detección de patróns e tendencias.
- Mellora da consistencia de datos: permite asegurar que existe integridade referencial e que se seguen, por exemplo, formatos similares en tipos de datos entre os datos a través de múltiples columnas.
- Redución de dimensionalidad: permite reducir o número de columnas que conteñen datos redundantes ou que están altamente correlacionadas.
3. Perfilado de dependencias
O perfilado de dependencias enfócase en descubrir e validar relacións lóxicas entre diferentes columnas, como:
-
Descubrimento de claves alleas, que está orientado a establecer que valores ou combinacións de valores dun conxunto de columnas tamén aparecen no outro conxunto de columnas, un requisito previo para unha clave foránea. Por exemplo, na táboa Investigador, a columna ProyectoID contén os valores [101, 102, 101, 103]. Para establecer ProyectoID como clave allea, verificamos que estes valores tamén están presentes na columna ProyectoID da táboa Proxecto [101, 102, 103]. Como todos os valores coinciden, ProyectoID en Investigador pode ser unha clave allea que referencia a ProyectoID en Proxecto.
- Dependencias funcionais, que establece relacións na que o valor dunha columna depende do valor doutra. Así mesmo, úsase para a validación de regras específicas que deben cumprirse (por exemplo, un valor de desconto non debe exceder o valor total).
Canto aos principais beneficios no uso deste perfilado de datos destacan:
- Mellora da integridade referencial: permite asegurar que as relacións entre táboas sexan válidas e mantéñanse correctas.
- Validación de consistencia entra valores: permite garantir que os datos cumpren con determinadas restricións ou cálculos definidos pola organización.
- Optimización do repositorio de datos: permite mellorar a estrutura e deseño de bases de datos mediante a validación e axuste de dependencias.
Usos do perfilado de datos
Os estatísticos anteriormente citados poden utilizarse en múltiples ámbitos nas organizacións. Un caso de uso a destacar sería en iniciativas de ciencia ciencia de datos e enxeñaría de datos onde permite comprender a fondo as características dun conxunto de datos antes da súa análise ou modelado.
- Ao xerar estatísticas descritivas, identificar valores atípicos e faltantes, descubrir patróns ocultos, identificar e corrixir problemas, como valores nulos, duplicados e inconsistencias, o perfilado de datos facilita a limpeza e a preparación de datos, asegurando a súa calidade e consistencia.
- Ademais, é crucial para a detección temperá de problemas, como duplicados ou erros, e para a validación de supostos en proxectos de análises predictivo.
- Tamén é fundamental para a integración de datos provenientes de múltiples fontes, garantindo a súa coherencia e compatibilidade.
- No ámbito de goberno, xestión e calidade de datos, o perfilado pode axudar a establecer políticas e procedementos sólidos, mentres que no cumprimento normativo asegura que os datos respecten coas regulacións aplicables.
- Por último, en termos de xestión axuda a optimizar os procesos de extracción, transformación e carga (Extract, Transform and Load ou ETL en inglés), apoia a migración de datos entre sistemas e prepara conxuntos de datos para o machine learning e analíticas predictivas, mellorando a eficacia dos modelos e decisións baseadas en datos.
Diferenza entre perfilado de datos e avaliación de calidade de datos
En ocasións, este termo de perfilado de datos confúndese coa avaliación de calidade de datos. Mentres que o perfilado de datos céntrase en descubrir e entender os metadatos e as características dos datos, a avaliación de calidade de datos vai un paso máis aló e céntrase por exemplo en analizar se os datos cumpren con certos requisitos ou estándares de calidade predefinidos na organización a través das regras de negocio. Así mesmo, a avaliación de calidade de datos involucra verificar o valor de calidade para distintas características ou dimensións tales como as incluídas na especificación UNE 0081 : exactitude, completitud, consistencia ou actualidade, etc., e asegurando que os datos sexan aptos para o seu uso previsto na organización: analítica, intelixencia artificial, intelixencia de negocio, etc.
Herramientas ou solucións para perfilado de datos
Por último, existen diversas solucións (ferramentas, librarías, ou dependencias) open source destacadas para o perfilado de datos que facilitan o entendemento dos datos. Entre elas, destacan:
- Cuadrillas Profiling e YData Profiling que ofrecen informes detallados e visualizacións avanzadas en Python
- Great Expectations e Dataprep que permiten validar e preparar datos, asegurando a súa integridade no ciclo de vida
- R dtables que permite a xeración de informes detallados e visualizacións para a análise exploratorio e o perfilado de datos para o ecosistema R.
En resumo, o perfilado de datos é unha parte importante na análise exploratorio de datos que permite obter unha comprensión detallada da estrutura, contidos, etc. e que é recomendable ter en conta en iniciativas de análises de datos. É importante dedicar tempo a esta actividade, contando cos recursos e ferramentas necesarios, para ter un mellor coñecemento dos datos que se manexan e ser conscientes de que é unha técnica máis a utilizar como parte da xestión de calidade de datos, e que pode ser utilizada como un paso previo á avaliación de calidade de datos.

- Información e datos do sector público




