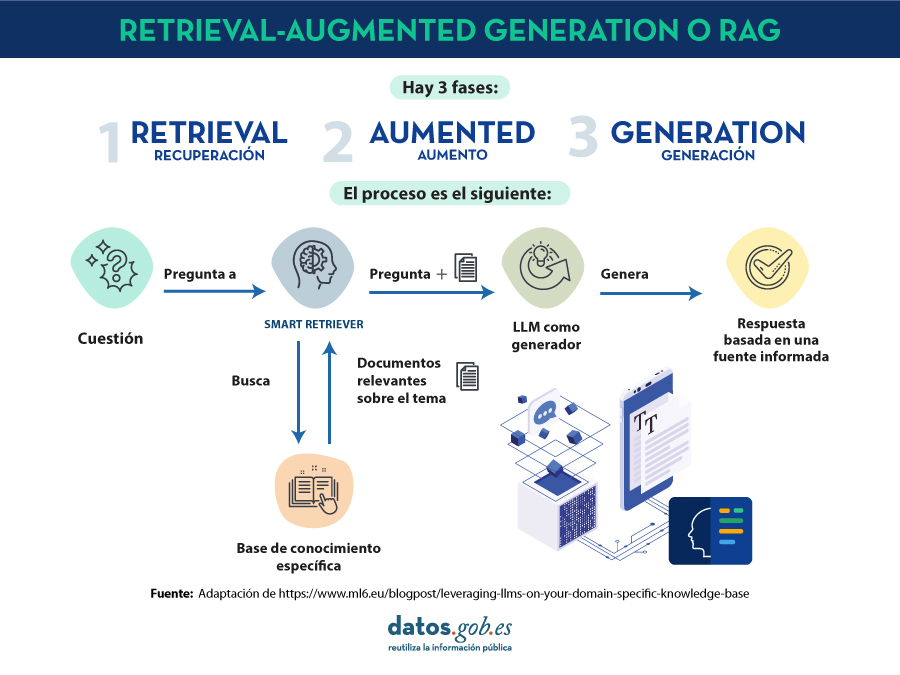
Introducción
En 2020, Patrick Lewis, un joven doctor en el campo de los modelos del lenguaje que trabajaba en la antigua Facebook AI Research (ahora Meta AI Research) publica junto a Ethan Perez de la Universidad de Nueva York un artículo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog , varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del
en el que explicaban una técnica para hacer más precisos y concretos los modelos del lenguaje actuales. El artículo es complejo para el público en general. Sin embargo, en su blog , varios de los autores del artículo explican de manera más asequible cómo funciona la técnica del
Los modelos grandes del lenguaje o Large Language Models son modelos de inteligencia artificial que se entrenan utilizando algoritmos de Deep Learning sobre conjuntos enormes de información generada por humanos. De esta manera, una vez entrenados, han aprendido la forma en la que los humanos utilizamos la palabra hablada y escrita, así que son capaces de ofrecernos respuestas generales y con un patrón muy humano a las preguntas que les hacemos. Sin embargo, si buscamos respuestas precisas en un contexto determinado, los . La prevalencia de la alucinación en los LLMs, estimada en un 15% o 20% para