
En la era digital actual, la información es un activo estratégico que impulsa la innovación, la transparencia y la colaboración en todos los sectores de la sociedad.
No obstante, existen aún muchos retos tanto para publicadores de datos como para consumidores de los mismos. Aspectos como el mantenimiento de las APIs (Application Programming Interfaces) que nos permiten acceder y consumir los conjuntos de datos publicados o la correcta replicación y sincronización de conjuntos de datos cambiantes siguen siendo desafíos muy relevantes para estos actores.
Los Linked Data Event Streams (LDES) son un nuevo mecanismo de publicación de datos que pueden ayudar a solventar estos retos.
Destilando los aspectos claves de LDES
Cuando desde la Universidad de Gante se comenzó a trabajar en un nuevo mecanismo para la publicación de datos abiertos, la pregunta a la que pretendían dar respuesta era: ¿Cuál es la mejor API posible que podemos diseñar para exponer conjuntos de datos abiertos?
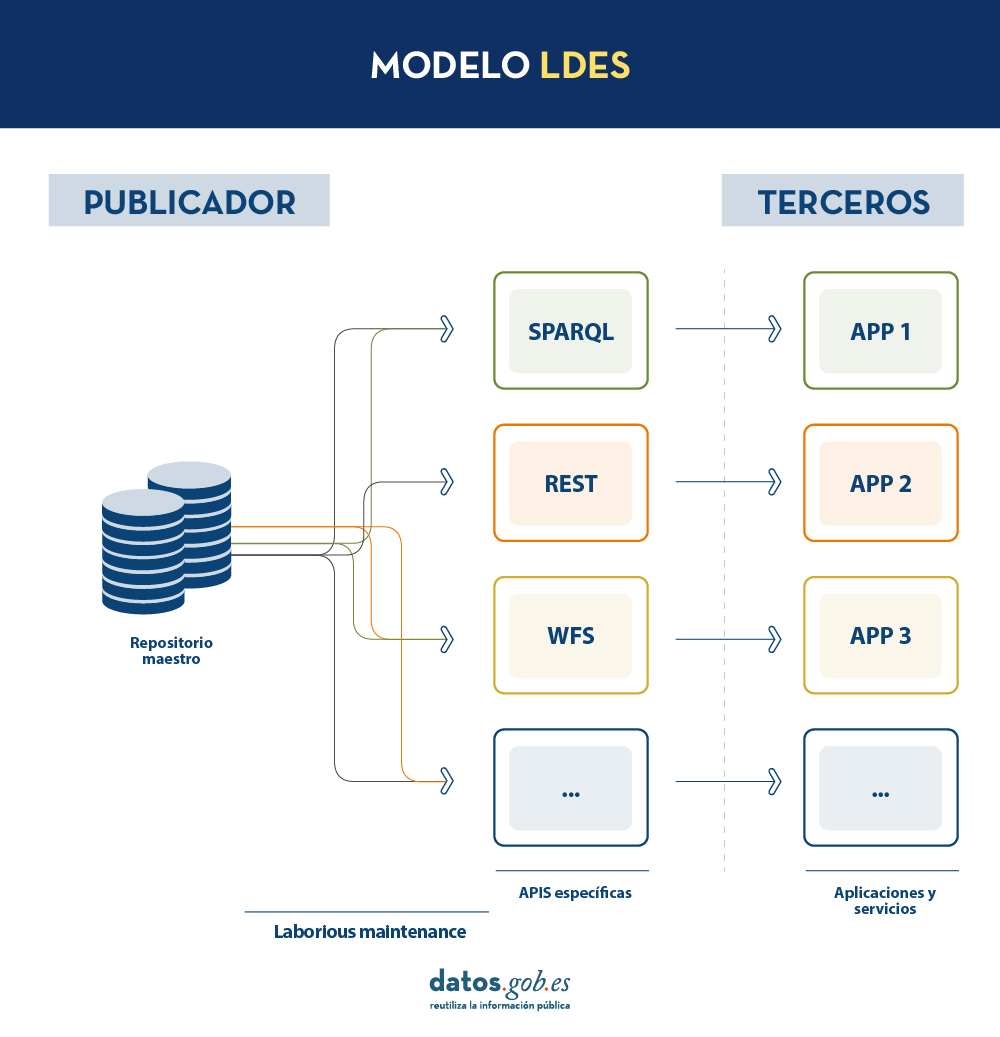
En la actualidad, los organismos publicadores de datos recurren a múltiples mecanismos para publicar sus diferentes conjuntos de datos. Por un lado, es fácil encontrarnos API s. Destacan las de tipo SPARQL, estándar para consulta de datos enlazados ( Link Data ), pero también de tipo REST o de tipo WFS, para el acceso a conjuntos de datos con componente geoespacial. Por otro lado, es muy común que encontremos la posibilidad de acceder a volcados de datos en diferentes formatos (i.e. CSV, JSON, XLS, etc.) que podamos descargar para su utilización.
En el caso de los volcados de datos, es muy fácil encontrarnos con problemas de sincronización. Esto ocurre cuando, tras un primer volcado, se produce un cambio que requiere la modificación del conjunto de datos original como, por ejemplo, el cambio del nombre de una calle en un callejero previamente descargado. Ante este cambio, si el tercero opta por modificar el nombre de la calle sobre el volcado inicial en lugar de esperar a que el publicador actualice sus datos en el repositorio maestro para realizar un nuevo volcado, los datos manejados por el tercero quedarán desincronizados frente a los manejados por el publicador. De igual forma, si es el publicador el que actualiza su repositorio maestro pero estos cambios no son descargados por el tercero, ambos manejarán diferentes versiones del conjunto de datos.
Por otra parte, si el publicador ofrece el acceso a los datos a través de APIs de consulta, en lugar de mediante volcados de los datos a los terceros, se solucionan los problemas de sincronización, pero la construcción y mantenimiento de un alto y variado volumen de las mismas supone un elevado esfuerzo a los publicadores de datos.
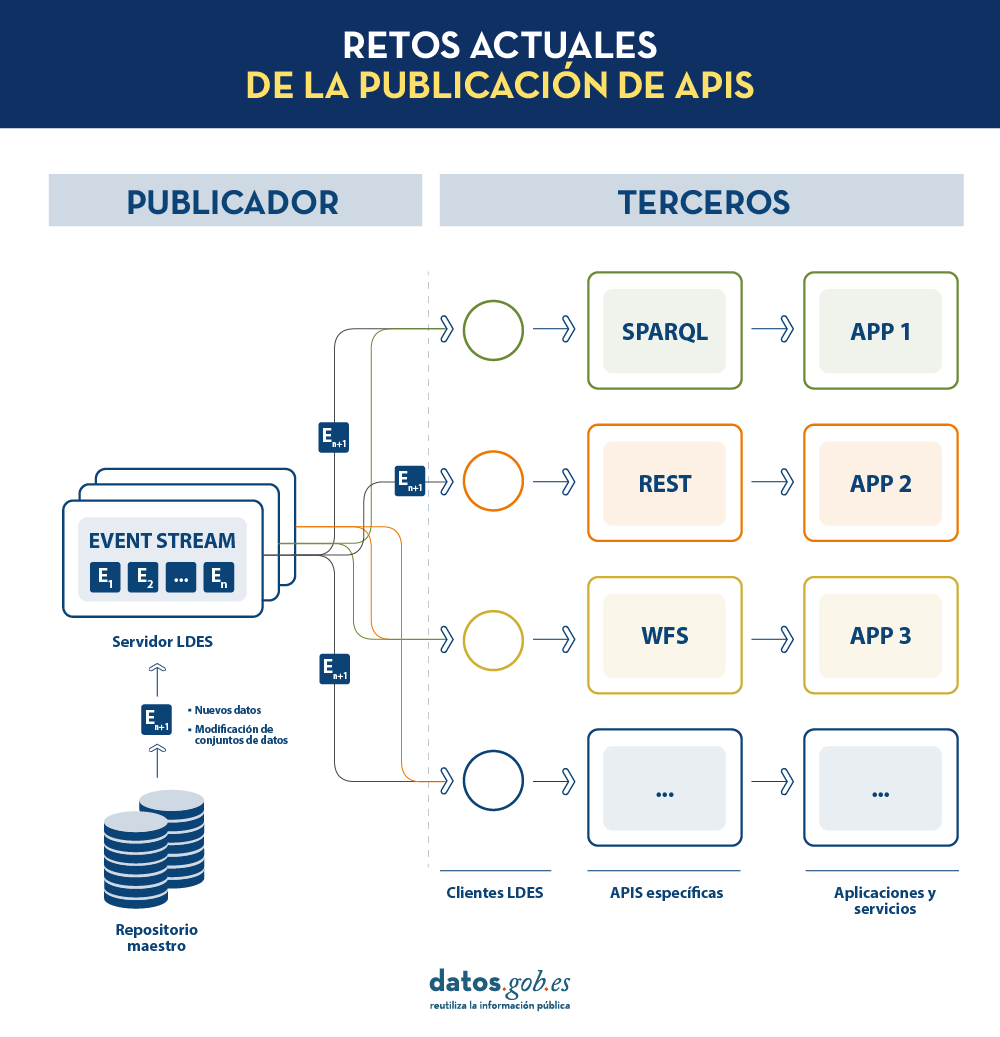
LDES busca solventar estas diferentes problemáticas aplicando el concepto de Linked Data a un event stream o flujo de datos. Según la definición que aparece en su propia especificación , un Linked Data Event Stream (LDES) es una colección de objetos inmutables donde cada objeto está descrito en ternas RDF.
En primer lugar, el hecho de que los LDES apuesten por Linked Data aporta principios de diseño que permiten combinar datos diversos y/o pertenecientes a diferentes fuentes, así como su consulta a través de mecanismos semánticos que permiten legibilidad tanto por humanos como por máquinas. En resumen, aporta interoperabilidad y consistencia entre conjuntos de datos, y facilita por tanto su búsqueda y descubrimiento.
Por otro lado, los event streams o flujos de datos, permiten a los consumidores replicar la historia de los conjuntos de datos, así como sincronizar los cambios recientes. Cualquier nuevo registro añadido a un conjunto de datos o cualquier modificación de los registros existentes (en definitiva, cualquier cambio), se registra como un nuevo evento incremental en el LDES que no alterará los eventos anteriores. Por tanto, pueden publicarse y consumirse datos como una secuencia de eventos, lo cual es útil para datos que cambian con frecuencia, como información en tiempo real o información que sufre actualizaciones constantes, ya que permite la sincronización de las últimas actualizaciones sin necesidad de hacer una nueva descarga completa de todo el repositorio maestro tras cada modificación.
En un modelo de este tipo, el editor solo necesitará desarrollar y mantener una API, el LDES, en lugar de múltiples APIs como WFS, REST o SPARQL. Los diferentes terceros que deseen utilizar los datos publicados se conectarán (cada tercero implementará su cliente LDES) y recibirán los eventos de los streams a los que se hayan suscrito. Cada tercero creará a partir de la información recabada las APIs específicas que considere oportunas en base al tipo de aplicaciones que quieran desarrollar o fomentar. En definitiva, el publicador no tendrá que resolver todas las potenciales necesidades que tenga cada tercero en la publicación de datos, sino que dando un interfaz LDES (API base mínima) cada tercero se centrará en su problemática.
Además, para facilitar el acceso en grandes volúmenes de datos o a datos que pueden estar distribuidos en diferentes fuentes, como un inventario de puntos de recarga eléctrica en Europa, LDES aporta la capacidad de fragmentación de los conjuntos de datos. A través de la especificación TREE (en inglés, árbol), LDES permite establecer diferentes tipos de relaciones entre fragmentos de datos. Esta especificación permite publicar colecciones de entidades, llamados miembros, y ofrece la capacidad de generar una o más representaciones de estas colecciones. Estas representaciones se organizan como vistas, distribuyendo los miembros a través de páginas o nodos interconectados mediante relaciones. Así, si deseamos que los datos se puedan consultar a través de índices temporales, se podrá establecer una fragmentación temporal y acceder solo a las páginas de un intervalo temporal. De igual forma, se podrán plantear índices alfabéticos o geoespaciales y así un consumidor podrá acceder sólo a aquellos datos necesarios sin la necesidad de realizar el “volcado” del conjunto de datos completo.
¿Qué conclusiones podemos extraer de LDES?
En este post hemos observado el potencial de LDES como mecanismo para la publicación de datos. Algunos de los aprendizajes más relevantes son:
- LDES persigue facilitar la publicación de datos a través de APIs base mínimas que sirvan como punto de conexión para cualquier tercero que desee consultar o construir aplicaciones y servicios sobre conjuntos de datos.
- La construcción de un servidor LDES, no obstante, tiene cierto nivel de complejidad técnica a la hora de establecer la arquitectura necesaria para el manejo de los flujos de datos publicados y su adecuada consulta por parte de consumidores de datos.
- El diseño de LDES permite la gestión tanto de datos con una elevada tasa de cambios (i.e. datos provenientes de sensores), como datos con una baja tasa de cambios (i.e. datos provenientes de un callejero). Ambos escenarios pueden manejar cualquier modificación del conjunto de datos como un flujo de datos.
- LDES soluciona de forma eficiente la gestión de registros históricos, versiones y fragmentos de conjuntos de datos. Para ello se apoya en la especificación TREE pudiendo establecer diferentes tipos de fragmentación sobre el mismo conjunto de datos.





