El perfilat de dades és el conjunt d'activitats i processos destinats a determinar les metadades sobre un conjunt concret de dades. Aquest procés, considerat com una tècnica indispensable durant l'anàlisi anàlisi exploratòria de dades , inclou l'aplicació de diferents estadístics amb el principal objectiu de determinar aspectes com el nombre de valors nuls, la quantitat de valors diferents en una columna, els tipus de dades i/o els patrons més freqüents dels valors de les dades. El seu objectiu final és proporcionar un enteniment clar i detallat de l'estructura, contingut i qualitat de les dades, la qual cosa és essencial abans del seu ús en qualsevol aplicació.
La importància del perfilat de dades, tipus i eines
13 juny 2024

El perfilat de dades és el conjunt d'activitats i processos destinats a determinar les metadades sobre un conjunt concret de dades.
Tipos de perfilat de dades
Existeixen diferents alternatives quant als principis estadístics a aplicar durant un perfilat de dades, així com la seva tipologia. Per a aquest article s'ha realitzat una revisió de diverses aproximacions de diferents autors. Sobre la base d'això, es decideix centrar l'article sobre la tipologia de tècniques de perfilat de dades en tres categories d'alt nivell: perfilat d'una columna, perfilat multicolumna i perfilat de dependències. Per a cada categoria s'identifiquen possibles tècniques i usos, com veurem a continuació.
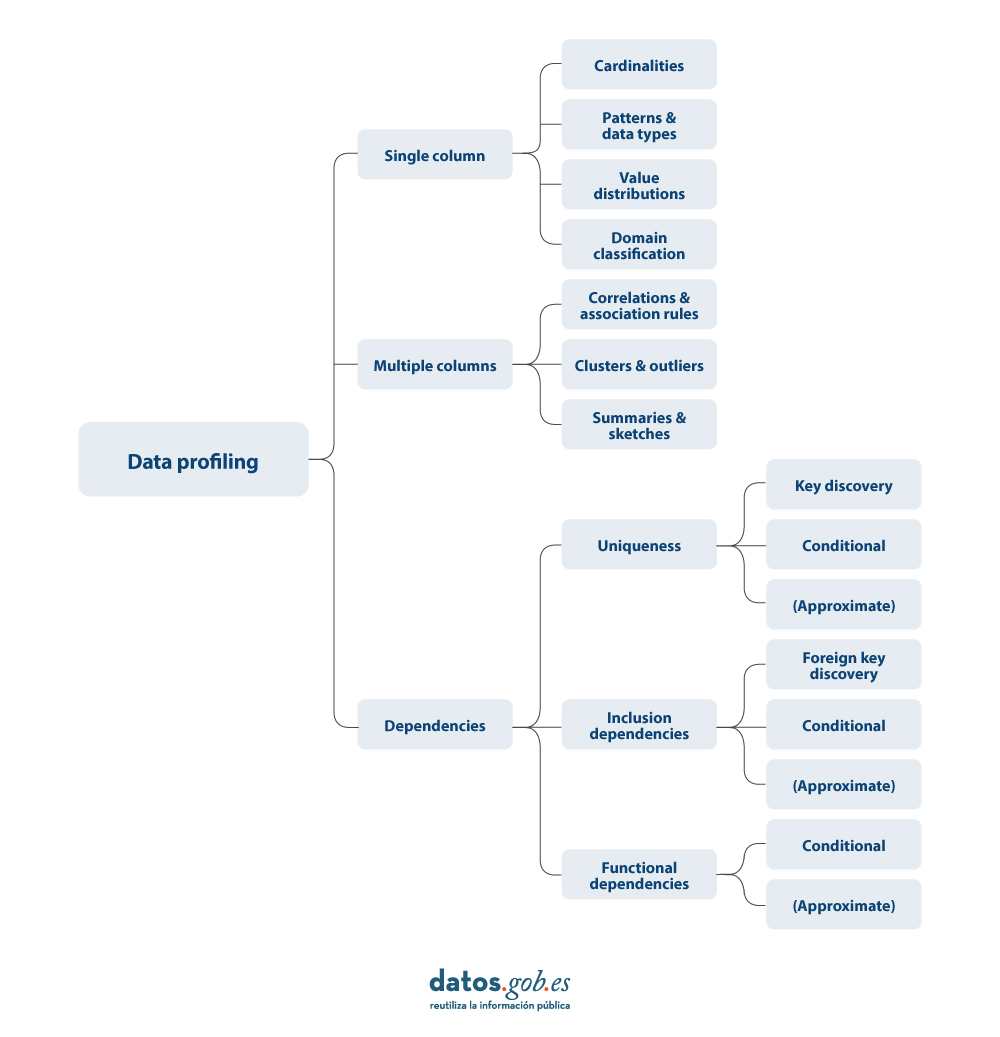
A continuació, es presenta més detall sobre cadascuna de les categories, així com els beneficis que aporten.
1. Perfilat d'una columna
El perfilat d'una columna se centra a analitzar cada columna d'un conjunt de dades de manera individual. Aquesta anàlisi inclou la recopilació de estadístiques descriptives com:
-
Conteo de valors diferents, per determinar el nombre exacte de registres únics d'una llista i poder classificar-los. Per exemple, en el cas d'un conjunt de dades que reculli les subvencions atorgades per un organisme públic, aquesta tasca ens permetrà saber quants beneficiaris diferents hi ha per a la columna de beneficiaris, i si algun es repeteix.
-
Distribució de valors (freqüència), que es refereix a l'anàlisi de la freqüència amb la qual ocorren diferents valors dins d'una mateixa columna. Això es pot representar mitjançant histogrames que divideixen els valors en intervals i mostren quants valors es troben en cada interval. Per exemple, en una columna d'edats, podríem trobar que 20 persones tenen entre 25-30 anys, 15 persones tenen entre 30-35 anys, etc.
-
Conteo de valors nuls o faltantes, la qual cosa implica explicar la quantitat de valors nuls o buits en cada columna d'un conjunt de dades. Ajuda a determinar la completesa de les dades i pot assenyalar possibles problemes de qualitat. Per exemple, en una columna d'adreces de correu electrònic, 5 de 100 registres podrien estar buits, indicant un 5% de dades faltantes.
- Longitud mínima, màxima i mitjana dels valors (per a columnes de text), la qual està orientada a calcular quin és la longitud dels valors en una columna de text. Això és útil per identificar valors inusuals i per definir restriccions de longitud en bases de dades. Per exemple, en una columna de noms, podríem trobar que el nom més curt té 3 caràcters, el més llarg 20 caràcters, i la mitjana és de 8 caràcters.
Quant als principals beneficis en l'ús d'aquest perfilat de dades destaquen:
- Detecció d'anomalies: permet la identificació de valors inusuals o fora de rang.
- Millora de la preparació de dades: ajuda en la normalització i neteja de dades abans del seu ús en anàlisis més avançades o en models de machine learning.
2. Perfilat multicolumna
El perfilat multicolumna analitza la relació entre dues o més columnes dins del mateix conjunt de dades. Aquest tipus de perfilat pot incloure:
- Anàlisi de correlació, utilitzat per identificar relacions entre columnes numèriques en un conjunt de dades. Una tècnica comuna és calcular correlacions per parells entre totes les columnes numèriques per descobrir patrons de relació. Per exemple, en una taula d'investigadors, podríem trobar que l'edat i el nombre de publicacions estan correlacionats, indicant que a mesura que augmenta l'edat dels investigadors i la seva categoria, també tendeix a augmentar el seu nombre de publicacions. Un coeficient de correlació de Pearson podria quantificar aquesta relació.
- Valors atípics (outliers), la qual cosa implica identificar dades que es desvien significativament d'altres punts de dades. Els outliers poden indicar errors, variabilitat natural o punts de dades interessants que mereixen una major recerca. Per exemple, en una columna de pressupostos per a projectes de R+D anuals, un valor d'un milió d'euros podria ser un outlier si la majoria dels ingressos es troben entre 30.000 i 100.000 euros. No obstant això, si es representa l'import en relació a la durada del projecte, podria ser un valor normal si el projecte d'un milió té 10 vegades la durada del de 100.000 euros.
- Detecció de combinacions de valors freqüents, enfocada a trobar conjunts de valors que ocorren junts amb freqüència en les dades. S'utilitzen per descobrir associacions entre elements, com en les dades de transaccions. Per exemple, en un conjunt de dades de compres, podríem trobar que els productes "bolquers" i "llet de fórmula per a bebès" es compren junts freqüentment. Un algorisme de regles d'associació podria generar la regla {bolquers} → {llet de fórmula}, indicant que els clients que compren pa també tendeixen a comprar mantega amb una alta probabilitat.
Quant als principals beneficis en l'ús d'aquest perfilat de dades destaquen:
- Detecció de tendències: permet identificar relacions i correlacions significatives entre columnes, la qual cosa pot ajudar en la detecció de patrons i tendències.
- Millora de la consistència de dades: permet assegurar que existeix integritat referencial i que se segueixen, per exemple, formats similars en tipus de dades entre les dades a través de múltiples columnes.
- Reducció de dimensionalidad: permet reduir el nombre de columnes que contenen dades redundants o que estan altament correlacionades.
3. Perfilat de dependències
El perfilat de dependències s'enfoca a descobrir i validar relacions lògiques entre diferents columnes, com:
-
Descobriment de claus alienes, que està orientat a establir què valors o combinacions de valors d'un conjunt de columnes també apareixen en l'altre conjunt de columnes, un requisit previ per a una clau forana. Per exemple, en la taula Investigador, la columna ProyectoID conté els valors [101, 102, 101, 103]. Per establir ProyectoID com a clau aliena, verifiquem que aquests valors també estan presents en la columna ProyectoID de la taula Projecto [101, 102, 103]. Com tots els valors coincideixen, ProyectoID en Investigador pot ser una clau aliena que referencia a ProyectoID en Projecte.
- Dependències funcionals, que estableix relacions en la qual el valor d'una columna depèn del valor d'una altra. Així mateix, s'usa per a la validació de regles específiques que han de complir-se (per exemple, un valor de descompte no ha d'excedir el valor total).
Quant als principals beneficis en l'ús d'aquest perfilat de dades destaquen:
- Millora de la integritat referencial: permet assegurar que les relacions entre taules siguin vàlides i es mantinguin correctes.
- Validació de consistència entra valors: permet garantir que les dades compleixen amb determinades restriccions o càlculs definits per l'organització.
- Optimització del repositori de dades: permet millorar l'estructura i disseny de bases de dades mitjançant la validació i ajust de dependències.
Usos del perfilat de dades
Els estadístics anteriorment citats poden utilitzar-se en múltiples àmbits en les organitzacions. Un cas d'ús a destacar seria en iniciatives de ciència de dades i enginyeria de dades on permet comprendre a fons les característiques d'un conjunt de dades abans de la seva anàlisi o modelatge.
- En generar estadístiques descriptives, identificar valors atípics i faltantes, descobrir patrons ocults, identificar i corregir problemes, com a valors nuls, duplicats i inconsistències, el perfilat de dades facilita la neteja i la preparació de dades, assegurant la seva qualitat i consistència.
- A més, és crucial per a la detecció primerenca de problemas, com a duplicats o errors, i per a la validació de supòsits en projectes d'anàlisi predictiva.
- També és fonamental per a la integració de dades provinents de múltiples fonts, garantint la seva coherència i compatibilitat.
- En l'àmbit de govern, gestió i qualitat de dades, el perfilat pot ajudar a establir polítiques i procediments sòlids, mentre que en el compliment normatiu assegura que les dades respectin amb les regulacions aplicables.
- Finalment, en termes de gestió ajuda a optimitzar els processos d'extracció, transformació i càrrega (Extract, Transform and Load o ETL en anglès), recolza la migració de dades entre sistemes i prepara conjunts de dades pel machine learning i analítiques predictives, millorant l'eficàcia dels models i decisions basades en dades.
Diferència entre perfilat de dades i avaluació de qualitat de dades
En ocasions, aquest terme de perfilat de dades es confon amb l'avaluació de qualitat de dades. Mentre que el perfilat de dades se centra a descobrir i entendre les metadades i les característiques de les dades, l'avaluació de qualitat de dades va un pas més enllà i se centra per exemple a analitzar si les dades compleixen amb certs requisits o estàndards de qualitat predefinits en l'organització a través de les regles de negoci. Així mateix, l'avaluació de qualitat de dades involucra verificar el valor de qualitat per a diferents característiques o dimensions tals com les incloses en especificació UNEIX 0081 : exactitud, completesa, consistència o actualitat, etc., i assegurant que les dades siguin aptes per al seu ús previst en l'organització: analítica, intel·ligència artificial, intel·ligència de negoci, etc.
Herramientas o solucions per perfilat de dades
Finalment, existeixen diverses solucions (eines, llibreries, o dependències) open source destacades per al perfilat de dades que faciliten l'enteniment de les dades. Entre elles, destaquen:
- Colles Profiling i YData Profiling que ofereixen informes detallats i visualitzacions avançades en Python
- Great Expectations i Dataprep que permeten validar i preparar dades, assegurant la seva integritat en el cicle de vida
- R dtables que permet la generació d'informes detallats i visualitzacions per a l'anàlisi exploratòria i el perfilat de dades per a l'ecosistema R.
En resum, el perfilat de dades és una part important en l'anàlisi exploratòria de dades que permet obtenir una comprensió detallada de l'estructura, continguts, etc. i que és recomanable tenir en compte en iniciatives d'anàlisis de dades. És important dedicar temps a aquesta activitat, comptant amb els recursos i eines necessaris, per tenir un millor coneixement de les dades que es manegen i ser conscients que és una tècnica més a utilitzar com a part de la gestió de qualitat de dades, i que pot ser utilitzada com un pas previ a l'avaluació de qualitat de dades.

- Informació i dades del sector públic




