El perfilado de datos es el conjunto de actividades y procesos destinados a determinar los metadatos sobre un conjunto concreto de datos. Este proceso, considerado como una técnica indispensable durante el análisis exploratorio de datos , incluye la aplicación de distintos estadísticos con el principal objetivo de determinar aspectos como el número de valores nulos, la cantidad de valores distintos en una columna, los tipos de datos y/o los patrones más frecuentes de los valores de los datos. Su objetivo final es proporcionar un entendimiento claro y detallado de la estructura, contenido y calidad de los datos, lo que es esencial antes de su uso en cualquier aplicación.
La importancia del perfilado de datos, tipos y herramientas
13 junio 2024

El perfilado de datos es el conjunto de actividades y procesos destinados a determinar los metadatos sobre un conjunto concreto de datos.
Tipos de perfilado de datos
Existen distintas alternativas en cuanto a los principios estadísticos a aplicar durante un perfilado de datos, así como su tipología. Para este artículo se ha realizado una revisión de varias aproximaciones de distintos autores. En base a ello, se decide centrar el artículo sobre la tipología de técnicas de perfilado de datos en tres categorías de alto nivel: perfilado de una columna, perfilado multicolumna y perfilado de dependencias. Para cada categoría se identifican posibles técnicas y usos, como veremos a continuación.
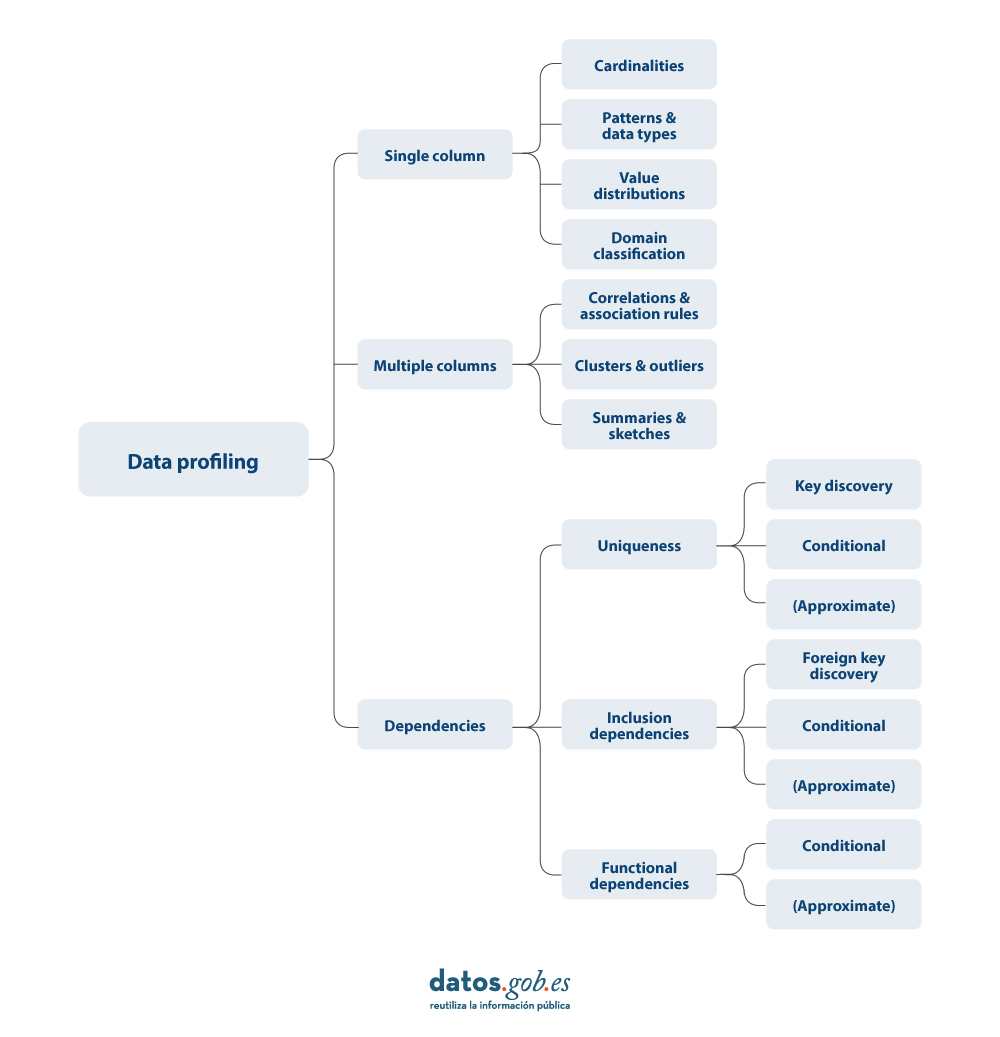
A continuación, se presenta más detalle sobre cada una de las categorías, así como los beneficios que aportan.
1. Perfilado de una columna
El perfilado de una columna se centra en analizar cada columna de un conjunto de datos de manera individual. Este análisis incluye la recopilación de estadísticas descriptivas como:
-
Conteo de valores distintos, para determinar el número exacto de registros únicos de una lista y poder clasificarlos. Por ejemplo, en el caso de un conjunto de datos que recoja las subvenciones otorgadas por un organismo público, esta tarea nos permitirá saber cuántos beneficiarios distintos hay para la columna de beneficiarios, y si alguno se repite.
-
Distribución de valores (frecuencia), que se refiere al análisis de la frecuencia con la que ocurren diferentes valores dentro de una misma columna. Esto se puede representar mediante histogramas que dividen los valores en intervalos y muestran cuántos valores se encuentran en cada intervalo. Por ejemplo, en una columna de edades, podríamos encontrar que 20 personas tienen entre 25-30 años, 15 personas tienen entre 30-35 años, etc.
-
Conteo de valores nulos o faltantes, lo que implica contar la cantidad de valores nulos o vacíos en cada columna de un conjunto de datos. Ayuda a determinar la completitud de los datos y puede señalar posibles problemas de calidad. Por ejemplo, en una columna de direcciones de correo electrónico, 5 de 100 registros podrían estar vacíos, indicando un 5% de datos faltantes.
- Longitud mínima, máxima y promedio de los valores (para columnas de texto), la cual está orientada a calcular cuál es la longitud de los valores en una columna de texto. Esto es útil para identificar valores inusuales y para definir restricciones de longitud en bases de datos. Por ejemplo, en una columna de nombres, podríamos encontrar que el nombre más corto tiene 3 caracteres, el más largo 20 caracteres, y el promedio es de 8 caracteres.
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Detección de anomalías: permite la identificación de valores inusuales o fuera de rango.
- Mejora de la preparación de datos: ayuda en la normalización y limpieza de datos antes de su uso en análisis más avanzados o en modelos de machine learning.
2. Perfilado multicolumna
El perfilado multicolumna analiza la relación entre dos o más columnas dentro del mismo conjunto de datos. Este tipo de perfilado puede incluir:
- Análisis de correlación, utilizado para identificar relaciones entre columnas numéricas en un conjunto de datos. Una técnica común es calcular correlaciones por pares entre todas las columnas numéricas para descubrir patrones de relación. Por ejemplo, en una tabla de investigadores, podríamos encontrar que la edad y el número de publicaciones están correlacionados, indicando que a medida que aumenta la edad de los investigadores y su categoría, también tiende a aumentar su número de publicaciones. Un coeficiente de correlación de Pearson podría cuantificar esta relación.
- Valores atípicos (outliers), lo cual implica identificar datos que se desvían significativamente de otros puntos de datos. Los outliers pueden indicar errores, variabilidad natural o puntos de datos interesantes que merecen una mayor investigación. Por ejemplo, en una columna de presupuestos para proyectos de I+D anuales, un valor de un millón de euros podría ser un outlier si la mayoría de los ingresos se encuentran entre 30.000 y 100.000 euros. Sin embargo, si se representa el importe en relación a la duración del proyecto, podría ser un valor normal si el proyecto de un millón tiene 10 veces la duración del de 100.000 euros.
- Detección de combinaciones de valores frecuentes, enfocada en encontrar conjuntos de valores que ocurren juntos con frecuencia en los datos. Se utilizan para descubrir asociaciones entre elementos, como en los datos de transacciones. Por ejemplo, en un conjunto de datos de compras, podríamos encontrar que los productos "pañales" y "leche de fórmula para bebés" se compran juntos frecuentemente. Un algoritmo de reglas de asociación podría generar la regla {pañales} → {leche de fórmula}, indicando que los clientes que compran pan también tienden a comprar mantequilla con una alta probabilidad.
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Detección de tendencias: permite identificar relaciones y correlaciones significativas entre columnas, lo que puede ayudar en la detección de patrones y tendencias.
- Mejora de la consistencia de datos: permite asegurar que existe integridad referencial y que se siguen, por ejemplo, formatos similares en tipos de datos entre los datos a través de múltiples columnas.
- Reducción de dimensionalidad: permite reducir el número de columnas que contienen datos redundantes o que están altamente correlacionadas.
3. Perfilado de dependencias
El perfilado de dependencias se enfoca en descubrir y validar relaciones lógicas entre diferentes columnas, como:
-
Descubrimiento de claves ajenas, que está orientado a establecer qué valores o combinaciones de valores de un conjunto de columnas también aparecen en el otro conjunto de columnas, un requisito previo para una clave foránea. Por ejemplo, en la tabla Investigador, la columna ProyectoID contiene los valores [101, 102, 101, 103]. Para establecer ProyectoID como clave ajena, verificamos que estos valores también están presentes en la columna ProyectoID de la tabla Proyecto [101, 102, 103]. Como todos los valores coinciden, ProyectoID en Investigador puede ser una clave ajena que referencia a ProyectoID en Proyecto.
- Dependencias funcionales, que establece relaciones en la que el valor de una columna depende del valor de otra. Así mismo, se usa para la validación de reglas específicas que deben cumplirse (por ejemplo, un valor de descuento no debe exceder el valor total).
En cuanto a los principales beneficios en el uso de este perfilado de datos destacan:
- Mejora de la integridad referencial: permite asegurar que las relaciones entre tablas sean válidas y se mantengan correctas.
- Validación de consistencia entra valores: permite garantizar que los datos cumplen con determinadas restricciones o cálculos definidos por la organización.
- Optimización del repositorio de datos: permite mejorar la estructura y diseño de bases de datos mediante la validación y ajuste de dependencias.
Usos del perfilado de datos
Los estadísticos anteriormente citados pueden utilizarse en múltiples ámbitos en las organizaciones. Un caso de uso a destacar sería en iniciativas de ciencia de datos e ingeniería de datos donde permite comprender a fondo las características de un conjunto de datos antes de su análisis o modelado.
- Al generar estadísticas descriptivas, identificar valores atípicos y faltantes, descubrir patrones ocultos, identificar y corregir problemas, como valores nulos, duplicados e inconsistencias, el perfilado de datos facilita la limpieza y la preparación de datos, asegurando su calidad y consistencia.
- Además, es crucial para la detección temprana de problemas, como duplicados o errores, y para la validación de supuestos en proyectos de análisis predictivo.
- También es fundamental para la integración de datos provenientes de múltiples fuentes, garantizando su coherencia y compatibilidad.
- En el ámbito de gobierno, gestión y calidad de datos, el perfilado puede ayudar a establecer políticas y procedimientos sólidos, mientras que en el cumplimiento normativo asegura que los datos respeten con las regulaciones aplicables.
- Por último, en términos de gestión ayuda a optimizar los procesos de extracción, transformación y carga (Extract, Transform and Load o ETL en inglés), apoya la migración de datos entre sistemas y prepara conjuntos de datos para el machine learning y analíticas predictivas, mejorando la eficacia de los modelos y decisiones basadas en datos.
Diferencia entre perfilado de datos y evaluación de calidad de datos
En ocasiones, este término de perfilado de datos se confunde con la evaluación de calidad de datos. Mientras que el perfilado de datos se centra en descubrir y entender los metadatos y las características de los datos, la evaluación de calidad de datos va un paso más allá y se centra por ejemplo en analizar si los datos cumplen con ciertos requisitos o estándares de calidad predefinidos en la organización a través de las reglas de negocio. Así mismo, la evaluación de calidad de datos involucra verificar el valor de calidad para distintas características o dimensiones tales como las incluidas en la especificación UNE 0081 : exactitud, completitud, consistencia o actualidad, etc., y asegurando que los datos sean aptos para su uso previsto en la organización: analítica, inteligencia artificial, inteligencia de negocio, etc.
Herramientas o soluciones para perfilado de datos
Por último, existen diversas soluciones (herramientas, librerías, o dependencias) open source destacadas para el perfilado de datos que facilitan el entendimiento de los datos. Entre ellas, destacan:
- Pandas Profiling e YData Profiling que ofrecen informes detallados y visualizaciones avanzadas en Python
- Great Expectations y Dataprep que permiten validar y preparar datos, asegurando su integridad en el ciclo de vida
- R dtables que permite la generación de informes detallados y visualizaciones para el análisis exploratorio y el perfilado de datos para el ecosistema R.
En resumen, el perfilado de datos es una parte importante en el análisis exploratorio de datos que permite obtener una comprensión detallada de la estructura, contenidos, etc. y que es recomendable tener en cuenta en iniciativas de análisis de datos. Es importante dedicar tiempo a esta actividad, contando con los recursos y herramientas necesarios, para tener un mejor conocimiento de los datos que se manejan y ser conscientes de que es una técnica más a utilizar como parte de la gestión de calidad de datos, y que puede ser utilizada como un paso previo a la evaluación de calidad de datos.

- Información y datos del sector público




