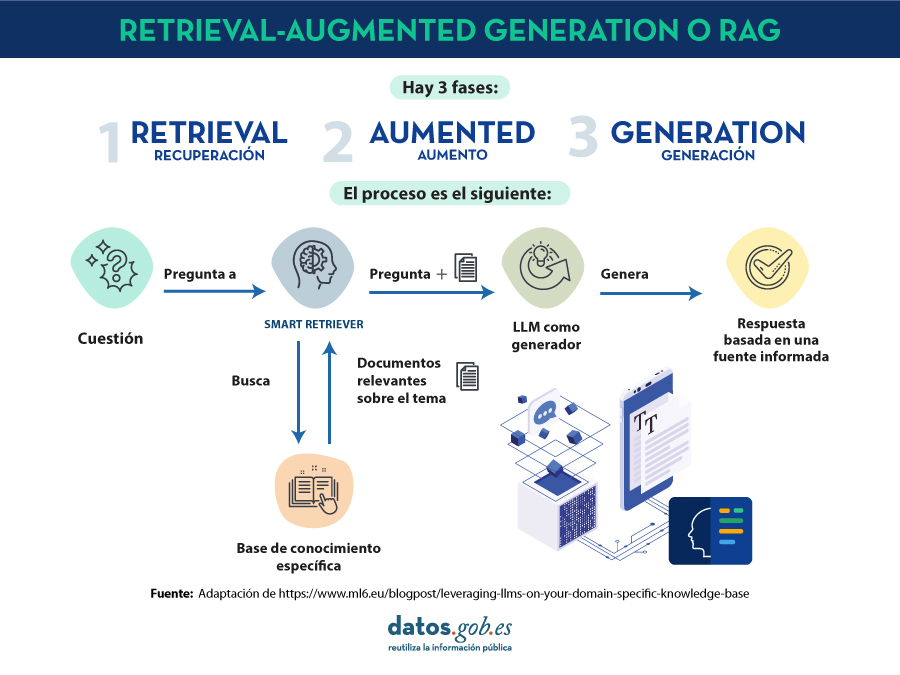
Introdución
En 2020, Patrick Lewis, un novo doutor no campo dos modelos da linguaxe que traballaba na antiga Facebook AI Research (agora Meta AI Research) publica xunto a Ethan Perez da Universidade de Nova York un artigo titulado: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks no que explicaban unha técnica para facer máis precisos e concretos os modelos da linguaxe actuais. O artigo é complexo para o público en xeral. Con todo, no seu blogue , varios dos autores do artigo explican de maneira máis alcanzable como funciona a técnica de o
no que explicaban unha técnica para facer máis precisos e concretos os modelos da linguaxe actuais. O artigo é complexo para o público en xeral. Con todo, no seu blogue , varios dos autores do artigo explican de maneira máis alcanzable como funciona a técnica de o
Os modelos grandes da linguaxe ou Large Language Models son modelos de intelixencia artificial que se adestran utilizando algoritmos de Deep Learning sobre conxuntos enormes de información xerada por humanos. Desta maneira, unha vez adestrados, aprenderon a forma na que os humanos utilizamos a palabra falada e escrita, así que son capaces de ofrecernos respostas xerais e con un patrón moi humano ás preguntas que lles facemos. Con todo, se buscamos respostas precisas nun contexto determinado, os
. A prevalencia da alucinación en os LLMs, estimada nun 15% ou 20% para